Simple auto scaling for Self-hosted Github Actions runner
회사에서 Github Enterprise (설치형)을 사용하고 있다. 버전 업그레이드 하면서 아마 재작년인가 작년인가부터 Github Actions를 사용할 수 있게 됐고, 젠킨스를 사용해 처리했단 PR 빌드를 Actions로 거의 다 대체한 상황이다. Actions runner는 k8s 위에 컨테이너로 올려뒀는데, 오토스케일링이 안되서 Actions runner 인스턴스를 무작정 늘려둘 수 밖에 없었다.
당연히 오토스케일링 정도는 지원해야 하는거 아닌가…? 싶었지만 아무튼 지원하지 않고, 공식 문서에선 오토 스케일링을 위한 몇가지 솔루션을 제안하고 있다.
Autoscaling with self-hosted runners
k8s 컨트롤러와 테라폼 모듈인데, 나는 사내 k8s paas를 사용하고 있기 때문에 컨트롤러를 설치하긴 어려울 것 같고 테라폼도 사용하지 않는다. 그래서 내가 생각했을 때 간단히 오토스케일링하기 위해서 아래와 같이 고민해봤다.
어떻게 오토스케일링 할 것인가?
Github actions runner는 크게 세 가지 상태로 구분할 수 있을 것 같다.
- Active: runner가 워크플로우를 수행 중인 상태
- Idle: runner가 워크플로우를 수행하고 있지 않음
- Offline: runner와의 연결이 끊김
내가 원하는건 Active/Idle의 상태를 추적하고, Idle 상태의 인스턴스 개수를 보장하는 것이다.
Active/Idle 상태 추적하기
사실 github actions metrics exporter라고 검색해보면 사람들이 만들어둔 소스가 많다. 이런걸 써도 되지만 간단히 스크립트로도 아래와 같이 작성할 수 있다.
runner 컨테이너에 들어가보면 Active 상태일 때 Runner.Worker라는 프로세스가 실행 중이다.
$ ps -ef
UID PID PPID C STIME TTY TIME CMD
...
user 98 93 0 08:03 ? 00:00:06 /home/user/apps/bin/Runner.Listener run
user 64324 98 41 15:49 ? 00:00:03 /home/user/apps/bin/Runner.Worker spawnclient 106 110
...
이 프로세스의 유무로 runner 인스턴스가 busy(워크플로우 수행 중)인지 확인할 수 있다.
아래 명령으로 .busy 파일에 Active: 1, Idle: 0로 적어둘 수 있다.
$ ps -ef | grep [R]unner.Worker | wc -l > $HOME/shared/.busy
그리고 이 명령을 actions runner 컨테이너의 liveness probe로 정의해두면, 정해둔 시간마다 명령을 실행해서 러너 상태를 업데이트 할 수 있다.
아래는 1초마다 명령을 실행해서 상태를 업데이트하는 스니핏이다.
containers:
# 생략...
- name: github-action-runner
livenessProbe:
exec:
command:
- /bin/bash
- -c
- "ps -ef | grep [R]unner.Worker | wc -l > $HOME/shared/.busy"
periodSeconds: 1
failureThreshold: 5
# 생략...
volumeMounts:
- name: shared-volume
mountPath: /home/user/shared
# 생략...
이렇게 하면 기본적으로 상태 추적을 할 수 있는 상태가 됐다.
그리고 위 코드 스니핏에 shared-volue이라고 정의해둔게 있는데, emptyDir 볼륨에 .busy 파일을 두고 다른 컨테이너에서도 이 파일에 접근할 수 있게 했다.
prometheus metrics server
위에서 만든 .busy 파일로 간단하게 메트릭을 내보낼 수 있다.
메트릭 서버는 파일에서 값(0 or 1)을 읽어서 지정한 메트릭 이름과 함께 아래와 같이 결과를 출력할 것이다.
$curl localhost:8000/metrics
github_actions_runner_busy{group="action-runner-group-a"} 0
서버는 nodejs를 사용해서 만든다. wikipedia의 Nodejs 문서를 보면 간단한 웹 서버를 만드는 코드 예제가 있다. 2015년에 본 것 같은데 이제야 써본다.
아래는 파일을 읽어서 runner 상태를 출력하는 코드이다.
사실 /metrics end point가 아니더라도 무조건 출력하긴 하지만… 파드 내부에서만 사용하는거라 간단하게 만들었다.
// server.js
const http = require('http');
const fs = require('fs')
const group = process.env['RUNNER_GROUP'] ?? 'default'
http.createServer(function (request, response) {
let busy = 1
try {
const busy = fs.readFileSync(filePath)
response.writeHead(200, {'Content-Type': 'text/plain'});
response.end(`github_actions_runner_busy{group="${group}"} ${busy.toString()}`);
} catch (e) {
console.error('File read error', e)
response.writeHead(500)
}
}).listen(8000);
console.log('Server running at http://localhost:8000/');
프로메테우스 exporter는 만드는 방법을 공홈에서 제공하고 있고, 각 언어별로 관련 라이브러리가 있다. 하지만 하나의 메트릭만 간단하게 서빙하는거라 라이브러리는 따로 사용하지 않았다.
이제 이거로 HPA 오브젝트를 만들고 promQL로 쿼리하는 구성이면 된다.
아래 블로그에서처럼 프로메테우스 메트릭을 이용해서 hpa를 구성할 수 있다. Kubernetes HPA with Custom Metrics from Prometheus
예를들면 아래 HPA는 파드가 모두 Active 상태이면, 2배로 인스턴스를 확장한다.
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: myapplication-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapplication-deployment
minReplicas: 3
maxReplicas: 15
metrics:
- type: Pods
pods:
metricName: github_actions_runner_busy
targetAverageValue: "500m"
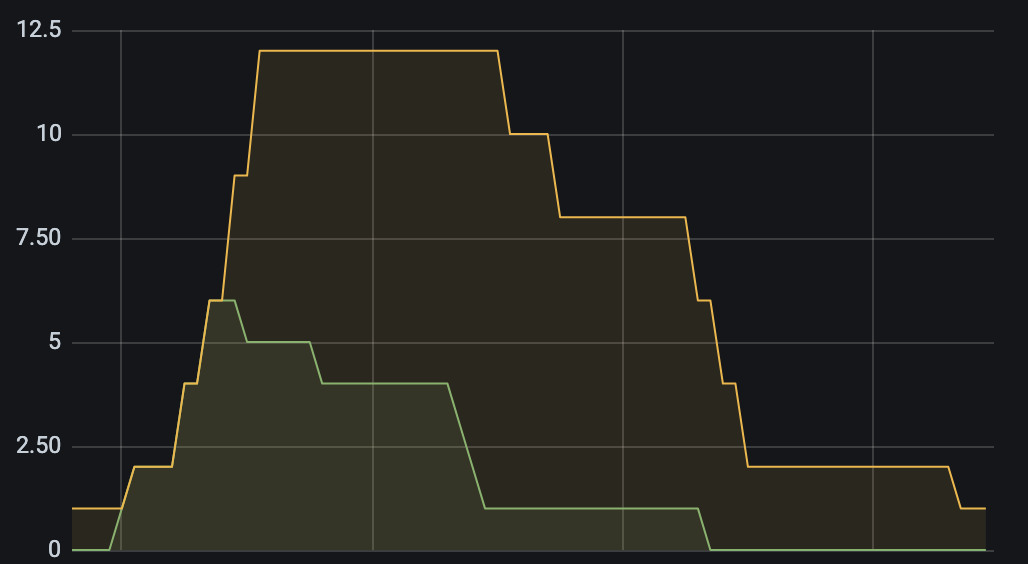
grafana로 메트릭 추이를 보면 Active runner 수에 따라 2배씩 확장을 하다 워크플로우나 끝나면 천천히 스케일 다운을 진행한다.